Approach
SlowFast Context Modeling
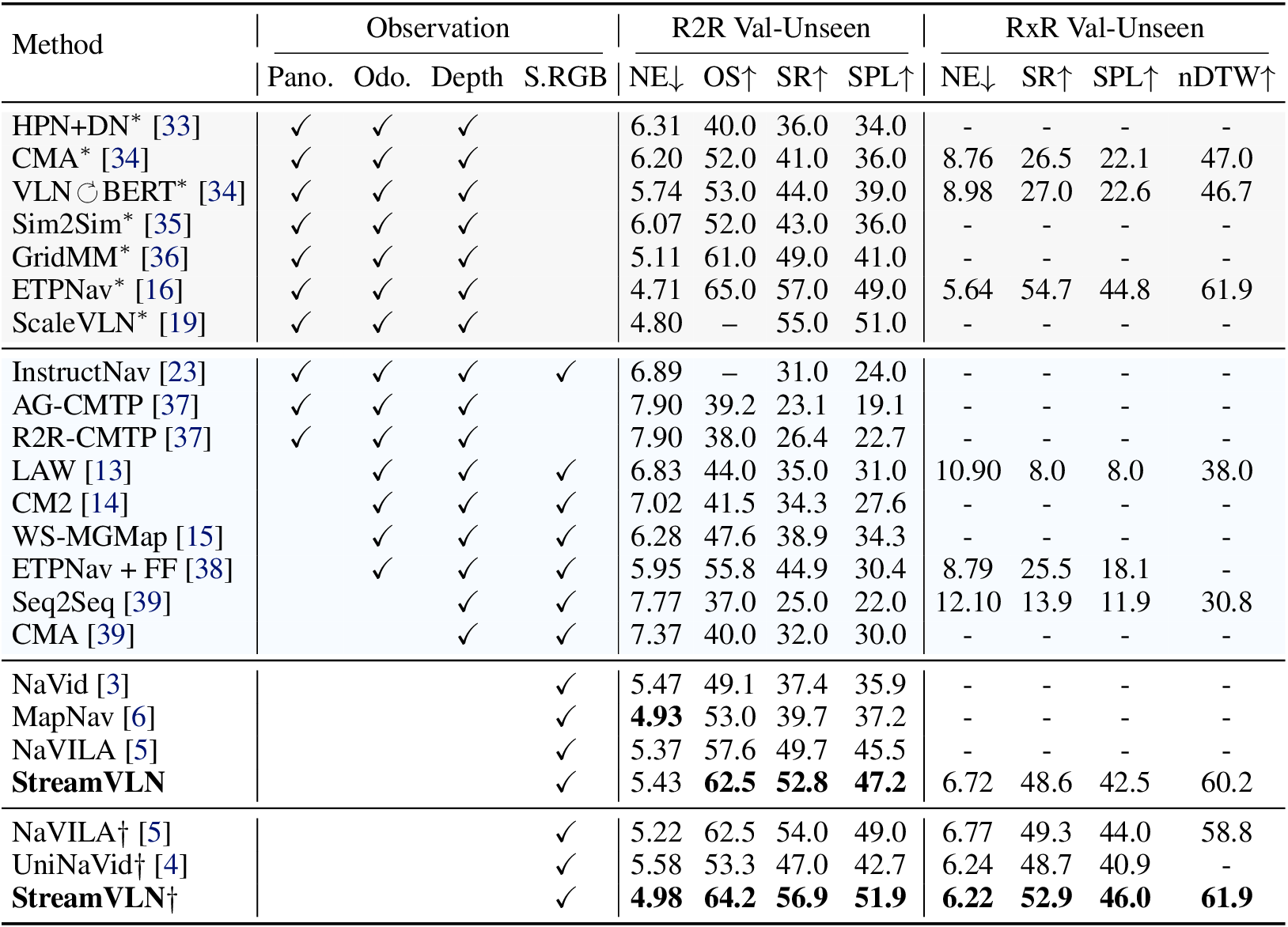
StreamVLN generates action outputs from continuous video input in an online, multi-turn dialogue manner. Built on LLaVA-Video as the foundational Video-LLM, we extend it for interleaved vision, language, and action modeling. For both effective context modeling of long sequence and efficient computation for real-time interaction, StreamVLN has: (1) a fast-streaming dialogue context with a sliding-window KV cache; and (2) a slow-updating memory via token pruning.
Data Collection
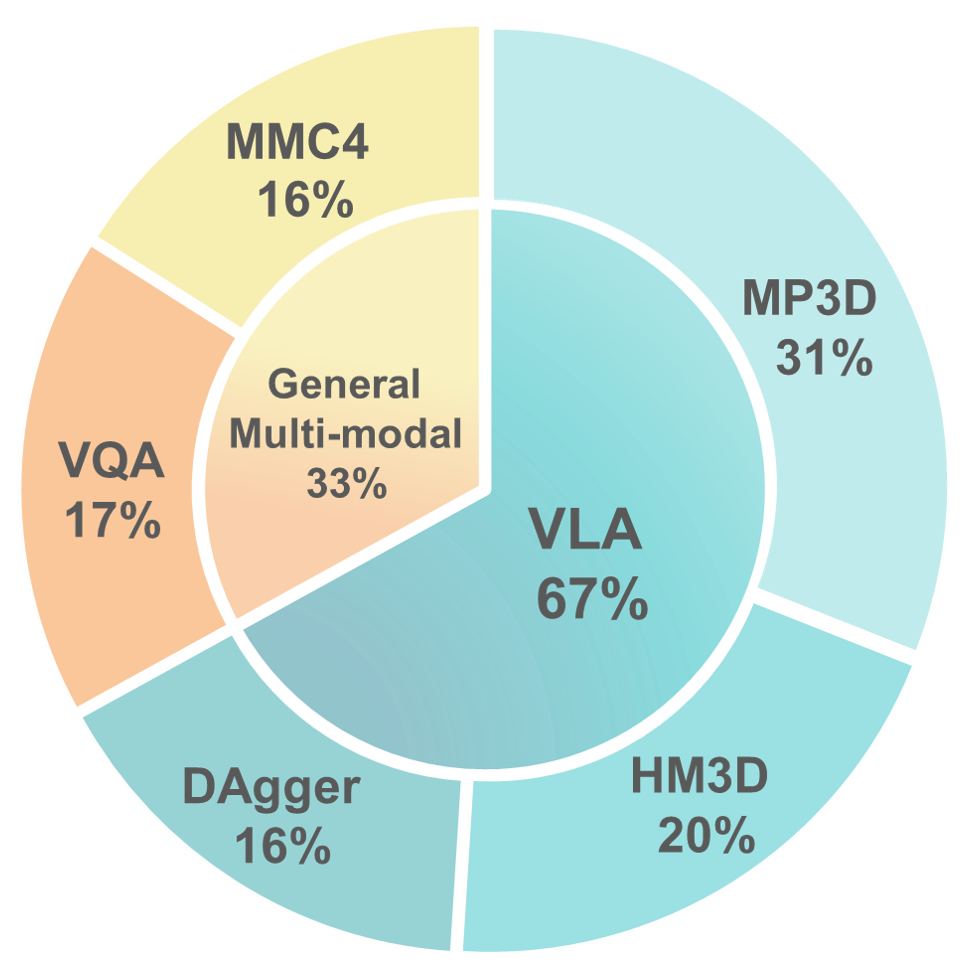
We incorporates both navigation-specific data samples and general multi-modal data samples in our training data.
For navigation-specific data, we collect 450K video clips from R2R, R2R-EnvDrop, RxR and ScaleVLN as expert training data, and 240K DAgger data samples as augmentation.
For general multi-modal data, we incorporate 248K video-based VQA samples from LLaVA-Video-178K and ScanQA, and 230K interleaved image-text samples from MMC4.The table below shows details of our data compositiion.
| Data Type | Source | Samples | Purpose |
|---|---|---|---|
| Navigation (Oracle) |
R2R
R2R-EnvDrop
RxR
ScaleVLN (subset)
|
450K | General navigation skills |
| Navigation (DAgger) | - | 240K | Error correction |
| Video QA |
LLaVA-Video-178K
ScanQA
|
248K | Spatiotemporal reasoning |
| Interleaved Image-Text |
MMC4
|
230K | Multi-turn dialog |